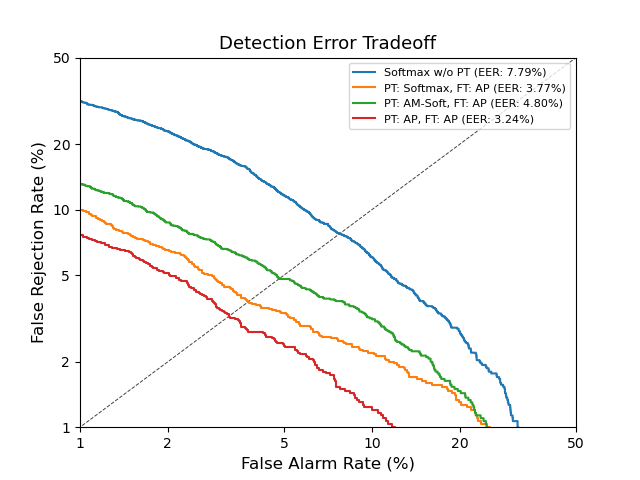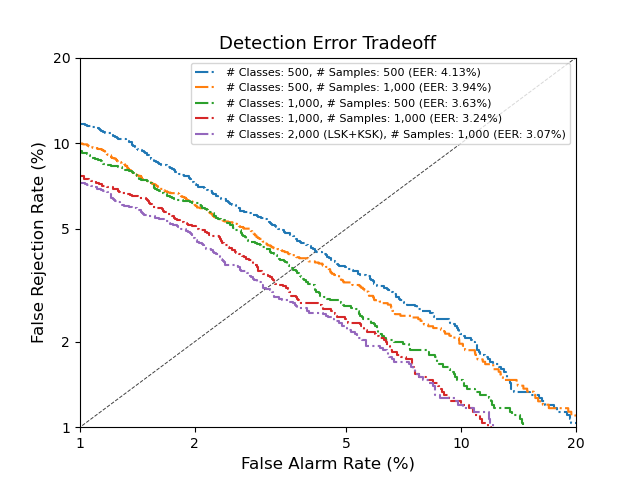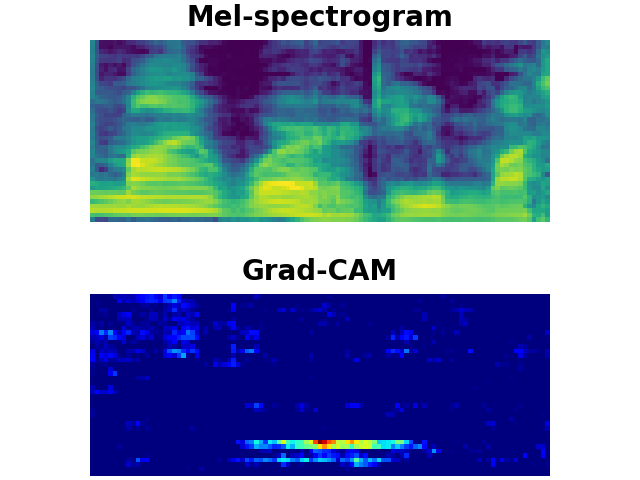
LibriSpeech Keywords (LSK) : Grad-CAM
WORD
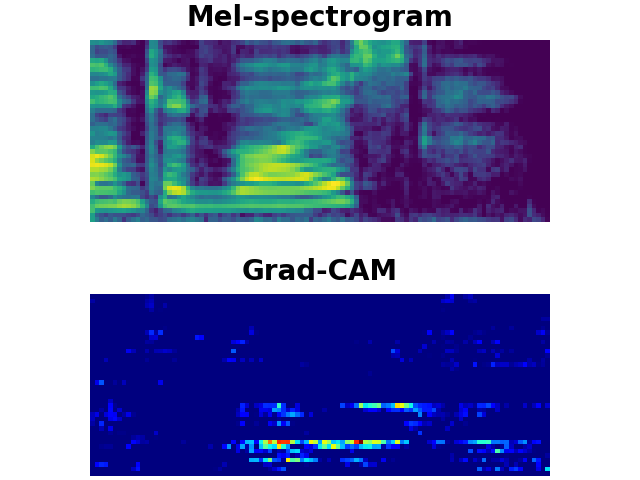
VOICE
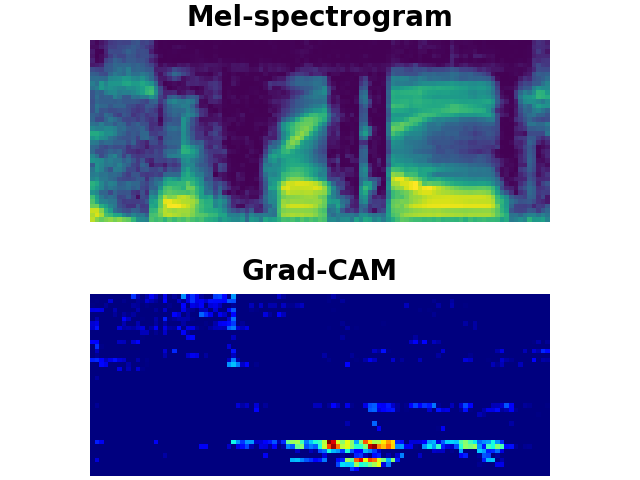
GREAT
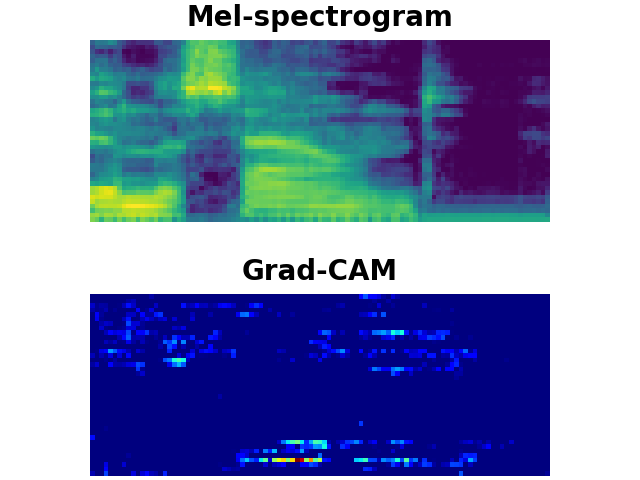
SOUND
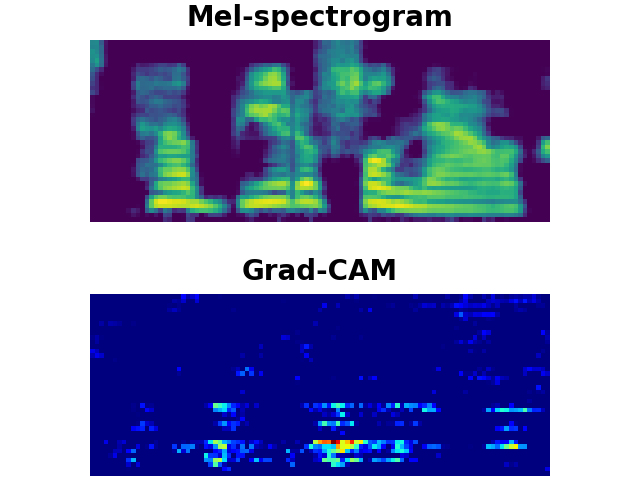
BEAUTIFUL
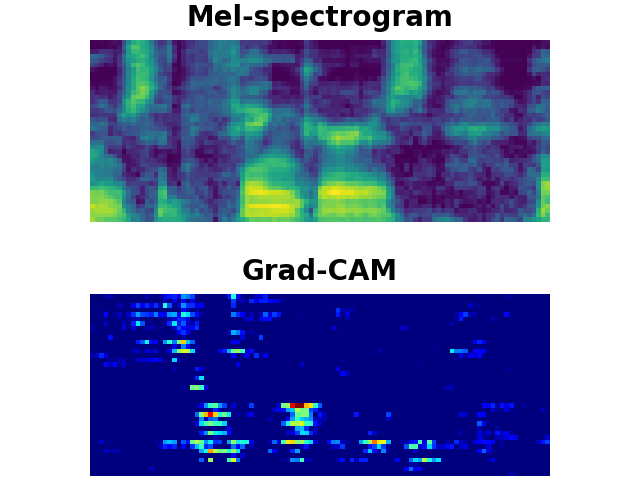
FINGERS
LSK dataset consists of 1 second keyword audio samples which include noises or utterances that may occur before or after the keywords in a real-world scenario. We utilise Grad-CAM to visually show whether the model can detect the exact part of user-defined keywords from the input audios. As shown above, the model trained on our LSK dataset focuses on where the target keywords are spotted.