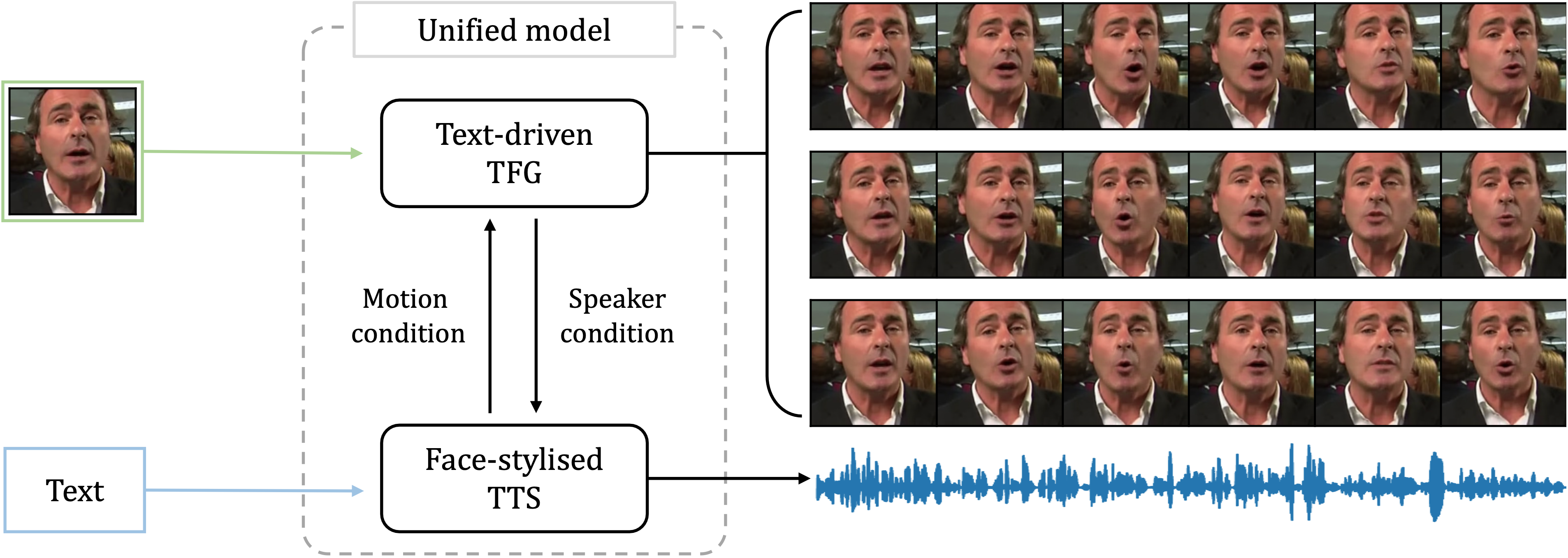
The goal of this work is to simultaneously generate natural talking faces and speech outputs from text. We achieve this by integrating Talking Face Generation (TFG) and Text-to-Speech (TTS) systems into a unified framework. We address the main challenges of each task: (1) generating a range of head poses representative of real-world scenarios, and (2) ensuring voice consistency despite variations in facial motion for the same identity. To tackle these issues, we introduce a motion sampler based on conditional flow matching, which is capable of high-quality motion code generation in an efficient way. Moreover, we introduce a novel conditioning method for the TTS system, which utilises motion-removed features from the TFG model to yield uniform speech outputs. Our extensive experiments demonstrate that our method effectively creates natural-looking talking faces and speech that accurately match the input text. To our knowledge, this is the first effort to build a multimodal synthesis system that can generalise to unseen identities.
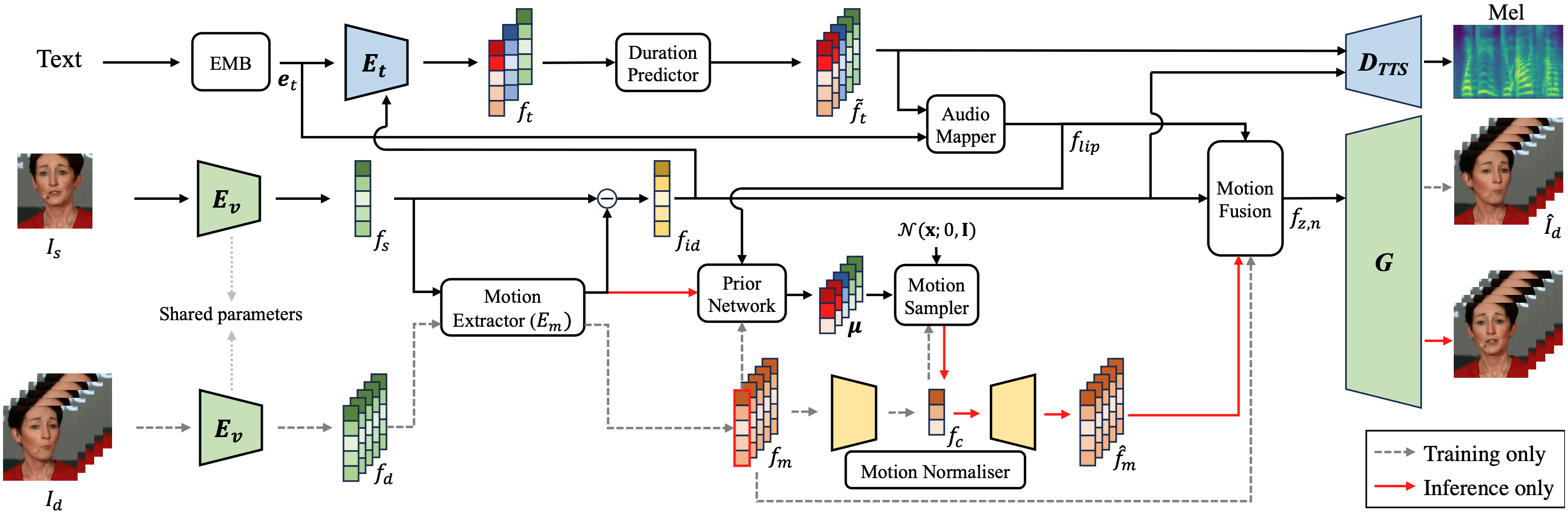
The TTS model receives identity representations from the TFG model, while the TFG model takes conditions for natural motion generation from the TTS model. These complementary elements enhance our model’s capabilities in generating both speech and talking faces. The EMB block denotes an embedding operation. The grey dashed arrow represents a path used only during the training process, and the red arrows represent paths used only during the inference process.