Overview
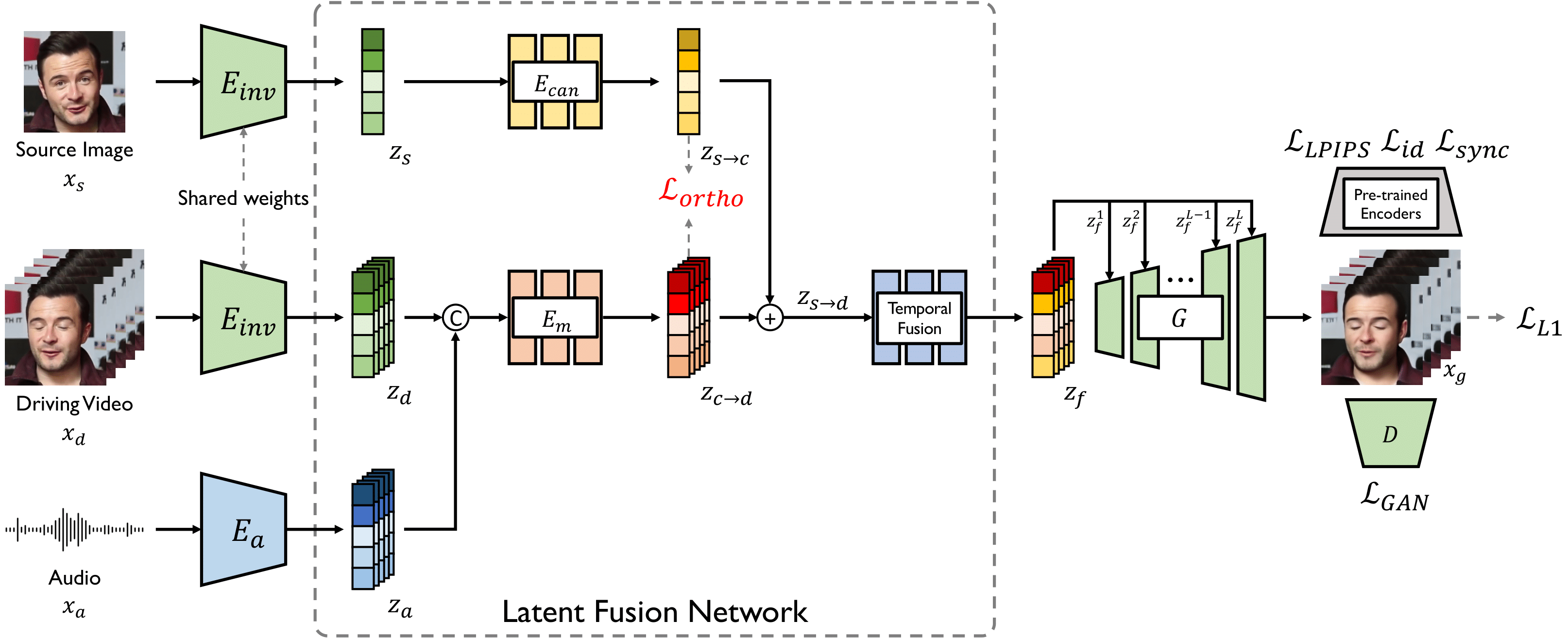
The key to our framework is two mapping operations: 1) Visual Space to Canonical Space, 2) Visual/Audio Space to Multimodal Motion Space. Through the first mapping, we obtain canonical images that have the same motion features and different identities. Meanwhile, the second mapping yields motion vectors that enable us to transfer desired motions onto canonical images. To ensure the disentanglement of the two subspaces, we impose an orthogonality constraint. Based on this process, our model is capable of generating talking faces that mimic the facial motion of the target.
Same-Identity Reconstruction
Cross-Identity Generation
Samples in Canonical Space
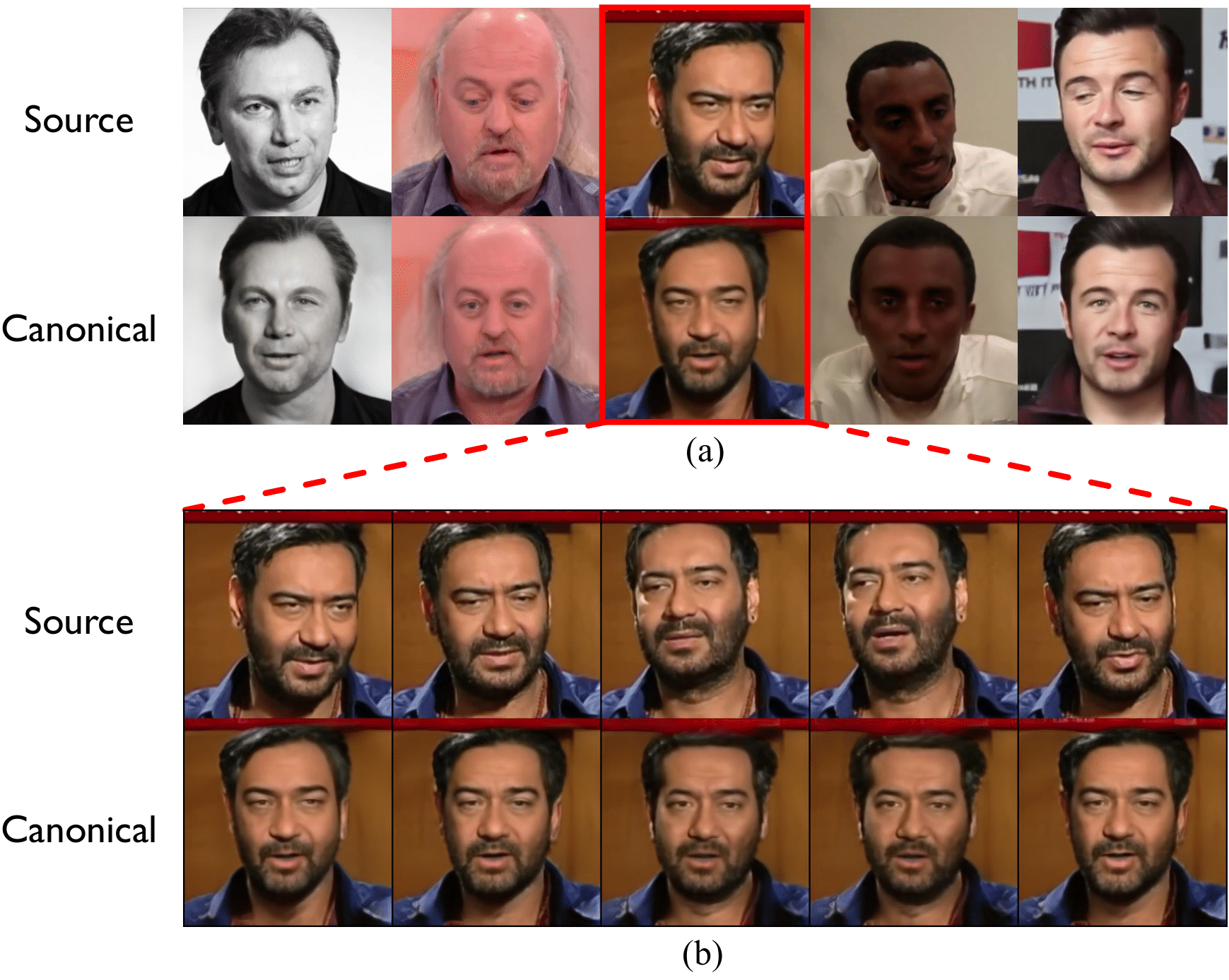
We demonstrate how well our model preserves identity by mapping various identities to the canonical space. In Fig. (a), we generate diverse canonical image samples having different identities by feeding each canonical code to our generator. In Fig. (b), we further visualise every canonical image from a single video. These results prove that our model is robust to maintain the source identities and well-generalised to various identities.
Comparison with SOTA